
How to represent survival rates in a fact table?
4 posters
Page 1 of 1

How to represent survival rates in a fact table?
![]() Al Wood Wed Nov 02, 2011 9:30 am
Al Wood Wed Nov 02, 2011 9:30 am
Hi,
I'm reviewing a design of a fact table to show the survival rates of patients.
The survival measures are durations measured from referral date, or from first medical treatment date, up to date of death.
The fact table has one row per patient, so the surrogate key for patient is actually unique in the table.
It has many bit columns such as [survival after one month], [survival after one year], [survival after two years], etc.
It also has columns for [referral date key], [referral type key], [first treatment date key], [treatment type key], etc.
In all it has 60 columns. I am sure this is too many.
But if the design was conceptually much simpler, so for example we had a referral fact table, and a treatment fact table, and the date of death was an attribute in the patient dimension, then the SQL query to determine for example survival rate after one month would be like this:
-- survival 1 month after treatment
select [Casenote Number]
--, datediff(day, fd.first_trt_date, [Date of Death]) as [survival days after treatment]
, case
when [Date of Death] is null then 1
when datediff(day, fd.first_trt_date, [Date of Death]) > 30 then 1
else 0
end as [survival 1 month after first treatment]
from (select min([date]) as first_trt_date, t.patient_sk from dbo.fact_trt t group by t.patient_sk) fd
inner join dbo.dim_patient p on p.patient_sk = fd.patient_sk
Using SSAS to build a cube from this ... harder than Vulcan Chess!
Can anyone suggest a design that allows survival rates to be queried easily, and cubed easily?
Al Wood
I'm reviewing a design of a fact table to show the survival rates of patients.
The survival measures are durations measured from referral date, or from first medical treatment date, up to date of death.
The fact table has one row per patient, so the surrogate key for patient is actually unique in the table.
It has many bit columns such as [survival after one month], [survival after one year], [survival after two years], etc.
It also has columns for [referral date key], [referral type key], [first treatment date key], [treatment type key], etc.
In all it has 60 columns. I am sure this is too many.
But if the design was conceptually much simpler, so for example we had a referral fact table, and a treatment fact table, and the date of death was an attribute in the patient dimension, then the SQL query to determine for example survival rate after one month would be like this:
-- survival 1 month after treatment
select [Casenote Number]
--, datediff(day, fd.first_trt_date, [Date of Death]) as [survival days after treatment]
, case
when [Date of Death] is null then 1
when datediff(day, fd.first_trt_date, [Date of Death]) > 30 then 1
else 0
end as [survival 1 month after first treatment]
from (select min([date]) as first_trt_date, t.patient_sk from dbo.fact_trt t group by t.patient_sk) fd
inner join dbo.dim_patient p on p.patient_sk = fd.patient_sk
Using SSAS to build a cube from this ... harder than Vulcan Chess!
Can anyone suggest a design that allows survival rates to be queried easily, and cubed easily?
Al Wood
Al Wood- Posts : 46
Join date : 2010-12-08
Re: How to represent survival rates in a fact table?
![]() ngalemmo Wed Nov 02, 2011 4:53 pm
ngalemmo Wed Nov 02, 2011 4:53 pm
If the fact contained date of treatment and date of death as dimensions (referencing a date dimension), and if the date dimension included attributes such as relative month, day, year, etc... it should be fairly easy to calculate the period between the two. Also, some SQLs now support INTERVAL data types which can be used to evaluate the span between two dates.

ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -

Accumulating fact
![]() elmorejr Wed Nov 02, 2011 5:40 pm
elmorejr Wed Nov 02, 2011 5:40 pm
Sounds like you could make use of an accumulating fact as well as a range dimension. I tried to represent your situation here and added in a few accumulating day interval facts to serve as values to represent days in between your patient events. I also added a DeathDate key. Finally, I added a new survival range dimension which can be used as a helpful filter in your fact queries. The actual # of days for survival can be found by adding each of the interval day facts together for a specific patient.
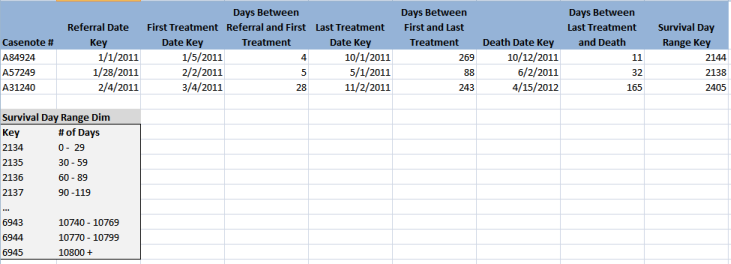
note: for simplicity, I used actual dates for the date key values, but of course this is not recomended
note: for simplicity, I used actual dates for the date key values, but of course this is not recomended
elmorejr- Posts : 25
Join date : 2011-10-20
Location : Columbus, Ohio, United States of America, Earth, Sol
Dimension table
![]() tlx814 Mon Nov 07, 2011 1:09 am
tlx814 Mon Nov 07, 2011 1:09 am
Al Wood wrote:The fact table has one row per patient, so the surrogate key for patient is actually unique in the table.
Regarding to this statement, is it a good practice or logical to view the first medical treatment date and the treatment type as attributes in patient dimension table and have TREATMENT_SK and in patient dimension table in snowflake dimension schema?
The reason I proposed this is 1) The first/last treatment information is more like the attribute of patients, rather than to represent a grain of the business process. 2) The SQL query would be simplified as
select datediff(day, first_trt_date, date_of_death) as survival_days,
case
when [Date of Death] is null then 1
when datediff(day, fd.first_trt_date, [Date of Death]) > 30 then 1
else 0
end as [survival 1 month after first treatment]
from dbo.dim_patient p
tlx814- Posts : 3
Join date : 2011-11-02
Re: How to represent survival rates in a fact table?
![]() Al Wood Tue Nov 08, 2011 10:37 am
Al Wood Tue Nov 08, 2011 10:37 am
Thanks all,
ngalemmo,
I like the idea of a [DateOfDeath] in the fact table. This would allow a more complex analysis that looked at survival of patients who had been referred, (and then treated) more than once.
I'm aware my query assumed every month has 30 days, but how would a "relative" month value help? Is that a month count from a fixed date in the past? Wouldn't "datediff(month..." give the same result? Or do you mean that we can't use the datediff function in the cube mdx query itself, but we can use simple subtraction?
Al Wood
ngalemmo,
I like the idea of a [DateOfDeath] in the fact table. This would allow a more complex analysis that looked at survival of patients who had been referred, (and then treated) more than once.
I'm aware my query assumed every month has 30 days, but how would a "relative" month value help? Is that a month count from a fixed date in the past? Wouldn't "datediff(month..." give the same result? Or do you mean that we can't use the datediff function in the cube mdx query itself, but we can use simple subtraction?
Al Wood
Al Wood- Posts : 46
Join date : 2010-12-08
» Multiple currency exchange rates in fact table
» How to represent boolean flag representation in FACT?
» Are "INTEREST RATES" fact or dimension attributes?
» 'Routing' the grain of the fact table to multpile members of multiple dimensions causes the fact table to 'explode'
» Integrating new fact table which has one to many relationship with the main fact table in existing star schema
» How to represent boolean flag representation in FACT?
» Are "INTEREST RATES" fact or dimension attributes?
» 'Routing' the grain of the fact table to multpile members of multiple dimensions causes the fact table to 'explode'
» Integrating new fact table which has one to many relationship with the main fact table in existing star schema
Page 1 of 1
Permissions in this forum:
You cannot reply to topics in this forum