
Heterogeneous Product Schema
4 posters
Page 1 of 1

Heterogeneous Product Schema
![]() mark.tan Tue Oct 06, 2009 9:37 am
mark.tan Tue Oct 06, 2009 9:37 am
Hi,
I am reading the Heterogenous Product Schema chapter from Kimball. I am trying to understand the design technique. Am I correct to that if I have many different type of dissimilar product, my design will look like this?
Fact Table
========
Month_SID
Prod1_SID
Prod2_SID
...
Core Facts
Prod1 Dim Table
============
Prod1_SID
...
Prod1 Attributes
Prod2 Dim Table
============
Prod2_SID
...
Prod2 Attributes
So when I insert 1 row in the fact table for Prod1, what value should I populate in the Prod2_SID and other heterogenous products? Do we just let it be 0?
Need some enlightenment.
Mark
I am reading the Heterogenous Product Schema chapter from Kimball. I am trying to understand the design technique. Am I correct to that if I have many different type of dissimilar product, my design will look like this?
Fact Table
========
Month_SID
Prod1_SID
Prod2_SID
...
Core Facts
Prod1 Dim Table
============
Prod1_SID
...
Prod1 Attributes
Prod2 Dim Table
============
Prod2_SID
...
Prod2 Attributes
So when I insert 1 row in the fact table for Prod1, what value should I populate in the Prod2_SID and other heterogenous products? Do we just let it be 0?
Need some enlightenment.
Mark

mark.tan- Posts : 14
Join date : 2009-02-04
Re: Heterogeneous Product Schema
![]() ngalemmo Tue Oct 06, 2009 11:05 am
ngalemmo Tue Oct 06, 2009 11:05 am
Re-read page 212, paragraph 2.
There is only one core product dimension with all products. Only one set of product keys and only one product foreign key in fact tables. There are, however, additional outrigger dimension tables containing attributes specific to a particular product. These outrigger tables contain the same primary key value that is carried for that product in the core product dimension. In ER terminology, the core dimension tables and its outriggers is a sub-type cluster.
When you query generic products, you join the fact to the core dimension using the product FK. When you are querying for a specific type of product you also join to the outrigger using the same key to get attributes unique to that product type. Using the outrigger join you also naturally restrict facts to that particular product type as the outrigger would not contain rows for other types.
There is only one core product dimension with all products. Only one set of product keys and only one product foreign key in fact tables. There are, however, additional outrigger dimension tables containing attributes specific to a particular product. These outrigger tables contain the same primary key value that is carried for that product in the core product dimension. In ER terminology, the core dimension tables and its outriggers is a sub-type cluster.
When you query generic products, you join the fact to the core dimension using the product FK. When you are querying for a specific type of product you also join to the outrigger using the same key to get attributes unique to that product type. Using the outrigger join you also naturally restrict facts to that particular product type as the outrigger would not contain rows for other types.

ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -

Re: Heterogeneous Product Schema
![]() mark.tan Tue Oct 06, 2009 10:46 pm
mark.tan Tue Oct 06, 2009 10:46 pm
Hi,
Thanks for the clarification!
So if I have more and more specific product, I will have more and more outrigger dimension tables or sub-type cluster?
Cheers,
Mark
Thanks for the clarification!
So if I have more and more specific product, I will have more and more outrigger dimension tables or sub-type cluster?
Cheers,
Mark
mark.tan- Posts : 14
Join date : 2009-02-04
Re: Heterogeneous Product Schema
![]() ngalemmo Wed Oct 07, 2009 12:47 am
ngalemmo Wed Oct 07, 2009 12:47 am
Yes, but don't overdo it. If there are classes of products that are very similar, in terms of their attributes, then you may want to group them into a single outrigger with a few columns that are not in common. It depends on what your source feeds look like and what makes sense.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
Still Unclear to me
![]() BiConsultant Sat Jul 31, 2010 6:00 pm
BiConsultant Sat Jul 31, 2010 6:00 pm
Hi Galemmo & Mark,
I am still bit confused about hetrogenous Schema, i have read this topic 3 times, but i am still unclear. Are we going to have three mini fact tables joined to main fact table, and three mini product dimension join to one product dimension.
Would it be possible for you to have some kind of diagram. I have already seen diagram presented on page 212-214, but i am still confused a bit.
I would really appreciate all your help understanding this scenario.
Thank You
Arif
I am still bit confused about hetrogenous Schema, i have read this topic 3 times, but i am still unclear. Are we going to have three mini fact tables joined to main fact table, and three mini product dimension join to one product dimension.
Would it be possible for you to have some kind of diagram. I have already seen diagram presented on page 212-214, but i am still confused a bit.
I would really appreciate all your help understanding this scenario.
Thank You
Arif
BiConsultant- Posts : 5
Join date : 2010-03-08
Re: Heterogeneous Product Schema
![]() BiConsultant Mon Aug 02, 2010 11:28 pm
BiConsultant Mon Aug 02, 2010 11:28 pm
Here is the model i came up with, its for bank with 3 line of products or business. CD, Loan and Deposit(Checking)
Let me know if something wrong with model.
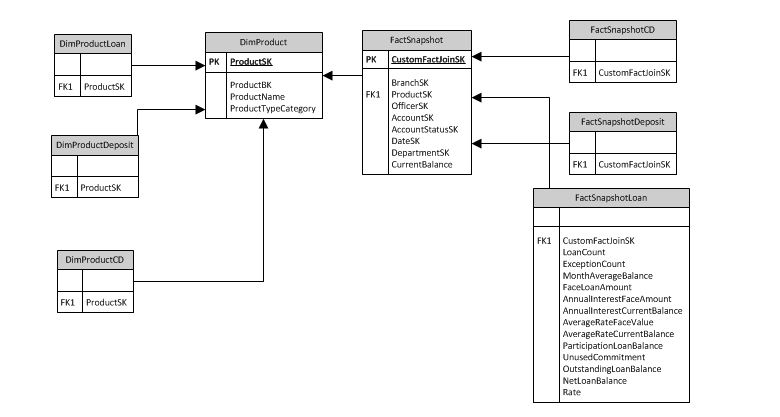
Let me know if something wrong with model.
BiConsultant- Posts : 5
Join date : 2010-03-08
Re: Heterogeneous Product Schema
![]() ngalemmo Tue Aug 03, 2010 11:48 am
ngalemmo Tue Aug 03, 2010 11:48 am
Yes, there is.
The PK of the subtype dimensions (DimProductLoan, Deposit and CD) should be the same as DimProduct. This allows you to join them directly to the fact using the existing FK to DimProduct. So if someone queries on attributes unique to a CD, they would only see fact rows related to CD products.
The other facts should not join to FactSnapshot, they should simply have whatever dimensions needed that are appropriate for those facts. The CustomFactJoinSK is not appropriate and unnecessary.
The PK of the subtype dimensions (DimProductLoan, Deposit and CD) should be the same as DimProduct. This allows you to join them directly to the fact using the existing FK to DimProduct. So if someone queries on attributes unique to a CD, they would only see fact rows related to CD products.
The other facts should not join to FactSnapshot, they should simply have whatever dimensions needed that are appropriate for those facts. The CustomFactJoinSK is not appropriate and unnecessary.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
Re: Heterogeneous Product Schema
![]() BiConsultant Tue Aug 03, 2010 1:41 pm
BiConsultant Tue Aug 03, 2010 1:41 pm
I am trying to keep the similar fact measures to core fact table and dissimilar fact measures in each custom fact table. If i am understanding you right that joinfactkey is unecessary, how would tell each core measures belongs to each custom fact measures?
BiConsultant- Posts : 5
Join date : 2010-03-08
Re: Heterogeneous Product Schema
![]() ngalemmo Tue Aug 03, 2010 2:04 pm
ngalemmo Tue Aug 03, 2010 2:04 pm
By the dimensions.
Measures "belong" to the dimensions, not other fact tables. At the atomic level, facts are tied to business processes. Since loans are most likely handled using a completely different process than, say, CD's, it is not unusual that it is supported by its own facts. If you need to also have an aggregate fact table that crosses all products, that's fine. The product dimension structure supports both.
Measures "belong" to the dimensions, not other fact tables. At the atomic level, facts are tied to business processes. Since loans are most likely handled using a completely different process than, say, CD's, it is not unusual that it is supported by its own facts. If you need to also have an aggregate fact table that crosses all products, that's fine. The product dimension structure supports both.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
Re: Heterogeneous Product Schema
![]() ngalemmo Tue Aug 03, 2010 2:25 pm
ngalemmo Tue Aug 03, 2010 2:25 pm
Here is how you should approach things...
You are doing a dimensional model. A dimensional DW is a collection of star schema. A star schema consists of ONE fact table and its associated dimensions (and the occasional bridge table, which sits between a fact table and a dimension table to resolve many-to-many relationships). An atomic fact table represents a specific business process, event or state. Star schema are related to each other through common conforming dimensions. There are no relationships between fact tables other than through conforming dimensions (which may be degenerate).
Dem is da rules.
So, identify the processes involved and model them individually. You are on the right track using a common product dimension with subtypes as product is a critical conforming dimension to allow integration and aggregation of facts. But, at the atomic level, the activity relating to a loan is very different from a deposit account. They have different base models, different stars, different measures, and a few non-conforming dimensions. Once you have modeled that, you have a foundation to identify commonalities and can create aggregate fact models that consolidate information from the atomic facts.
You are doing a dimensional model. A dimensional DW is a collection of star schema. A star schema consists of ONE fact table and its associated dimensions (and the occasional bridge table, which sits between a fact table and a dimension table to resolve many-to-many relationships). An atomic fact table represents a specific business process, event or state. Star schema are related to each other through common conforming dimensions. There are no relationships between fact tables other than through conforming dimensions (which may be degenerate).
Dem is da rules.
So, identify the processes involved and model them individually. You are on the right track using a common product dimension with subtypes as product is a critical conforming dimension to allow integration and aggregation of facts. But, at the atomic level, the activity relating to a loan is very different from a deposit account. They have different base models, different stars, different measures, and a few non-conforming dimensions. Once you have modeled that, you have a foundation to identify commonalities and can create aggregate fact models that consolidate information from the atomic facts.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
What about differentiating your PK's between each of the heterogenous dimensions
![]() stusco Tue Aug 03, 2010 11:55 pm
stusco Tue Aug 03, 2010 11:55 pm
Hi ngalemmo,
In an earlier thread you suggested the following:
"The PK of the subtype dimensions (DimProductLoan, Deposit and CD) should be the same as DimProduct. This allows you to join them directly to the fact using the existing FK to DimProduct. So if someone queries on attributes unique to a CD, they would only see fact rows related to CD products"
When you refer to PK do you mean the surrogate key or the business key? Whilst I subscribe to this approach, I'm struggling to see how this might be executed when the individual subtype dimensions are built independently of each other before DimProduct is populated, i.e. the generation of the surrogate keys using IDENTITTY (1,1) across 12 subtype dimensions will inevitably result in a substantial number of duplicates when the various subtype dimensions are subsequently consolidated into DimProduct (unless the proposal is that you build your DimProduct first and then propagate the heterogenous out to each of their respective subtype dimensions, in which case I guess that the SK would be unique...?).
Thanks,
Stuart
In an earlier thread you suggested the following:
"The PK of the subtype dimensions (DimProductLoan, Deposit and CD) should be the same as DimProduct. This allows you to join them directly to the fact using the existing FK to DimProduct. So if someone queries on attributes unique to a CD, they would only see fact rows related to CD products"
When you refer to PK do you mean the surrogate key or the business key? Whilst I subscribe to this approach, I'm struggling to see how this might be executed when the individual subtype dimensions are built independently of each other before DimProduct is populated, i.e. the generation of the surrogate keys using IDENTITTY (1,1) across 12 subtype dimensions will inevitably result in a substantial number of duplicates when the various subtype dimensions are subsequently consolidated into DimProduct (unless the proposal is that you build your DimProduct first and then propagate the heterogenous out to each of their respective subtype dimensions, in which case I guess that the SK would be unique...?).
Thanks,
Stuart
stusco- Posts : 2
Join date : 2010-08-03
Re: Heterogeneous Product Schema
![]() ngalemmo Wed Aug 04, 2010 11:37 am
ngalemmo Wed Aug 04, 2010 11:37 am
A dimension's PK is ALWAYS a surrogate key.
The process is as you describe in the latter part of your post. DimProduct exists before or in sync with the subtype tables and would be the source of the PK value. It has to be done this way, otherwise the keys get all messed up. The subtypes would not use an autogenerated number, instead, if you need to add a new subtype row, you would lookup the DimProduct entry and get the PK from there.
If you are trying to retrofit a common dimension, such as DimProduct to an existing schema with a bunch of subtype dimensions, you will need to add a new FK to the facts to reference the common dimension. Dealing with aggregations that include multiple subtypes can be problematic if the aggregations need subtype attributes that are not handled in the common dimension.
Some of those issues are discussed in the following article: http://intelligent-enterprise.informationweek.com/010613/warehouse1_1.jhtml
The process is as you describe in the latter part of your post. DimProduct exists before or in sync with the subtype tables and would be the source of the PK value. It has to be done this way, otherwise the keys get all messed up. The subtypes would not use an autogenerated number, instead, if you need to add a new subtype row, you would lookup the DimProduct entry and get the PK from there.
If you are trying to retrofit a common dimension, such as DimProduct to an existing schema with a bunch of subtype dimensions, you will need to add a new FK to the facts to reference the common dimension. Dealing with aggregations that include multiple subtypes can be problematic if the aggregations need subtype attributes that are not handled in the common dimension.
Some of those issues are discussed in the following article: http://intelligent-enterprise.informationweek.com/010613/warehouse1_1.jhtml
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
Handling Type 2 Changes
![]() stusco Thu Aug 05, 2010 9:18 pm
stusco Thu Aug 05, 2010 9:18 pm
Thanks for your reply Nick.
In that case, how would you propose that the following scenario be modelled...?
DimProduct represents a subset of common attributes that are found across all of the subtype dimensions. Some of these attributes are SCD type 2. Each of the subtype dimensions contain attributes that are specific to them and some of these are also SCD type 2. The changes that happen to the type 2 attributes in DimProduct will naturally generate new SK's as rows are expired. How do you track type 2 changes across all attributes (DimProduct and subtype dimensions) so that the SK's remain aligned (changes in DimProduct may not have the same timing as changes to the subtype dimension)?
Thanks
In that case, how would you propose that the following scenario be modelled...?
DimProduct represents a subset of common attributes that are found across all of the subtype dimensions. Some of these attributes are SCD type 2. Each of the subtype dimensions contain attributes that are specific to them and some of these are also SCD type 2. The changes that happen to the type 2 attributes in DimProduct will naturally generate new SK's as rows are expired. How do you track type 2 changes across all attributes (DimProduct and subtype dimensions) so that the SK's remain aligned (changes in DimProduct may not have the same timing as changes to the subtype dimension)?
Thanks
stusco- Posts : 2
Join date : 2010-08-03
Re: Heterogeneous Product Schema
![]() BiConsultant Thu Aug 05, 2010 10:48 pm
BiConsultant Thu Aug 05, 2010 10:48 pm
Thanks for replying ngalemmo,
You are absolutely right, perhaps i completely forgot to mention that, The core fact table is actually monthly snapshot, this is the reason I have modeled with core and custom fact for each product. I know custom join fact key is unecessary, but the reason i have it cause we will be feeding the cube through this and then reporting from cube unlike relation TSQL. so even if i do not create a relation here i will have to in SSAS. Some guys are confused here with SK in primary core product table and again in custom product dimension tables. Product Core dimension is set to identity auto increment, while custom product dimensions are just the copy of those productSK, means both matches for each product row. And once again i appreciate your valuable input and sharing your expert knowledge.
You are absolutely right, perhaps i completely forgot to mention that, The core fact table is actually monthly snapshot, this is the reason I have modeled with core and custom fact for each product. I know custom join fact key is unecessary, but the reason i have it cause we will be feeding the cube through this and then reporting from cube unlike relation TSQL. so even if i do not create a relation here i will have to in SSAS. Some guys are confused here with SK in primary core product table and again in custom product dimension tables. Product Core dimension is set to identity auto increment, while custom product dimensions are just the copy of those productSK, means both matches for each product row. And once again i appreciate your valuable input and sharing your expert knowledge.
BiConsultant- Posts : 5
Join date : 2010-03-08
Re: Heterogeneous Product Schema
![]() ngalemmo Fri Aug 06, 2010 1:04 pm
ngalemmo Fri Aug 06, 2010 1:04 pm
stusco wrote:Thanks for your reply Nick.
In that case, how would you propose that the following scenario be modelled...?
DimProduct represents a subset of common attributes that are found across all of the subtype dimensions. Some of these attributes are SCD type 2. Each of the subtype dimensions contain attributes that are specific to them and some of these are also SCD type 2. The changes that happen to the type 2 attributes in DimProduct will naturally generate new SK's as rows are expired. How do you track type 2 changes across all attributes (DimProduct and subtype dimensions) so that the SK's remain aligned (changes in DimProduct may not have the same timing as changes to the subtype dimension)?
Thanks
Fortunately, I have not encountered that situation. Interesting problem.
Offhand, it can think of two approaches.
1: Have a single fact FK and keep the main table and the subtype table in sync at all times. This would mean if there was a change to either table, both tables get type 2 treatment so the keys on both are the same.
2: Have two FKs on the fact. One for the main table and another for the subtype tables. But this introduces some challenges. The sequence used to assign subtype keys must be shared among all subtype tables so that the numbers are mutually exclusive, otherwise you could join to the wrong subtype. You would also need to allow for a null FK, or an invalid one, for products that that do not have a subtype dimension associated with it.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
» Applying the concept of heterogeneous product schema in manufacturing & supply chain
» Sparse Product Dim vs Heterogeneous Product Dim
» Modelling Heterogeneous Product table
» Product Dimensions - Single Product Code Mutliple Services
» Slowly changing heterogeneous dimensions
» Sparse Product Dim vs Heterogeneous Product Dim
» Modelling Heterogeneous Product table
» Product Dimensions - Single Product Code Mutliple Services
» Slowly changing heterogeneous dimensions
Page 1 of 1
Permissions in this forum:
You cannot reply to topics in this forum