
Data Modeling Question (Bridge Tables?) for Star Schema for Proposals/Awards for university
Page 1 of 1

Data Modeling Question (Bridge Tables?) for Star Schema for Proposals/Awards for university
![]() CSH Tue Jul 14, 2015 9:36 am
CSH Tue Jul 14, 2015 9:36 am
Our university has a need to report on the total number and dollar value of proposals and awards based on common filter criteria. To meet this need, we are proposing a star schema which will allow business users to easily retrieve answers to these sorts of queries.
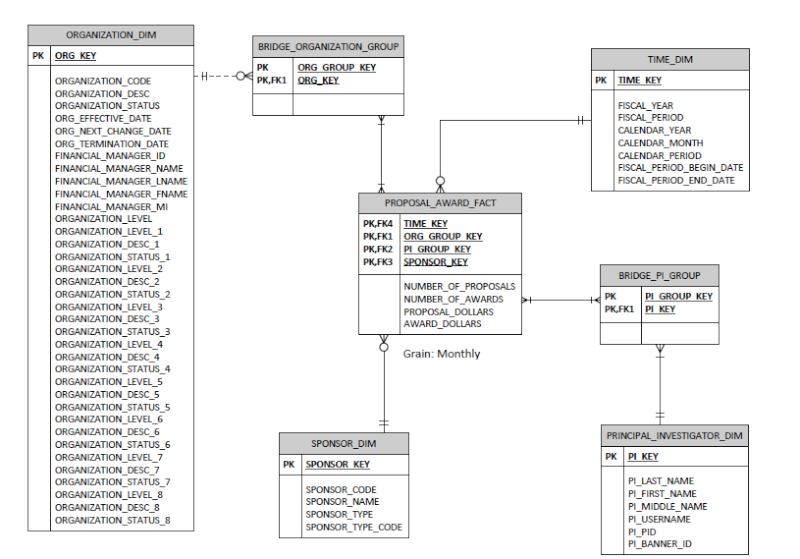
Our proposed design has at the center a PROPOSAL_AWARD_FACT table, which will aggregate the total number of proposals, total number of awards, total proposal dollars, and total award dollars at a monthly grain. (In general, these are proposals and awards for federal grants, though there can be private contracts, subcontracts, etc.) The dimensions based on business user requirements would be time, principal investigator (person who would manage the award), sponsor, and organization. For organization, we are planning to do a full load from our source database, which has history of all changes.
However, it is possible for multiple principal investigators to be involved in a single proposal or award. Furthermore, it is possible for multiple organizations to be involved in a single proposal or award. Because of this, we need to ensure that proposals and awards are not counted multiple times if this is the case, in order to avoid inflating the amount when reporting at a university level.
In order to simplify the question, lets focus on the principal investigator dimension. Business users have a need to view total award dollars for a given fiscal year for the entire university, but also have a need to view total award dollars for a given fiscal year for a specific principal investigator. When viewing total award dollars at the university level, we want to ensure that we do not double-count awards that are associated with multiple principal investigators. However, when counting total award dollars at the principal investigator level, the business users want to ensure that the award is counted for each principal investigator on the award. Would we be able to achieve this result through the use of a bridge table? Based on searching this forum for similar situations, we believe a bridge table should resolve this issue, but want to confirm that our thinking is correct...Our bridge table would assign a PI group key to a distinct group of PI's. Also, would you be able to provide any guidance on items to consider when determining whether to utilize weighting factors?
Below are some snippets as to how wed assume the data would look given our proposed design using a bridge table. (Test data with some columns removed for brevity)
PROPOSAL_AWARD_FACT
BRIDGE_PI_GROUP
PRINCIPAL_INVESTIGATOR_DIM
For our ETL process, we believe we would need another group table consisting of the PI_GROUP_KEY from the BRIDGE_PI_GROUP table, and a second column concatenating the values of the Principal Investigator natural key (PI_PID, in this case) in order to form distinct groups of PI's and assign a PI group key.
We believe that we would take the same approach to address this with our organization dimension (its basically the same issue) but were hoping to solicit feedback as to whether we are taking the correct approach in designing this? I'm inserting a screenshot of our proposed diagram below.
This is the first star schema I'll be working on, so any advice or feedback would be very much appreciated (especially related to whether the bridge table would work for our situation, but if you have other advice/feedback, I'd definitely appreciate that as well!). Thank you!
Our proposed design has at the center a PROPOSAL_AWARD_FACT table, which will aggregate the total number of proposals, total number of awards, total proposal dollars, and total award dollars at a monthly grain. (In general, these are proposals and awards for federal grants, though there can be private contracts, subcontracts, etc.) The dimensions based on business user requirements would be time, principal investigator (person who would manage the award), sponsor, and organization. For organization, we are planning to do a full load from our source database, which has history of all changes.
However, it is possible for multiple principal investigators to be involved in a single proposal or award. Furthermore, it is possible for multiple organizations to be involved in a single proposal or award. Because of this, we need to ensure that proposals and awards are not counted multiple times if this is the case, in order to avoid inflating the amount when reporting at a university level.
In order to simplify the question, lets focus on the principal investigator dimension. Business users have a need to view total award dollars for a given fiscal year for the entire university, but also have a need to view total award dollars for a given fiscal year for a specific principal investigator. When viewing total award dollars at the university level, we want to ensure that we do not double-count awards that are associated with multiple principal investigators. However, when counting total award dollars at the principal investigator level, the business users want to ensure that the award is counted for each principal investigator on the award. Would we be able to achieve this result through the use of a bridge table? Based on searching this forum for similar situations, we believe a bridge table should resolve this issue, but want to confirm that our thinking is correct...Our bridge table would assign a PI group key to a distinct group of PI's. Also, would you be able to provide any guidance on items to consider when determining whether to utilize weighting factors?
Below are some snippets as to how wed assume the data would look given our proposed design using a bridge table. (Test data with some columns removed for brevity)
PROPOSAL_AWARD_FACT
| TIME_KEY | PI_GROUP_KEY | SPONSOR_KEY | NUMBER_OF_AWARDS | AWARD_DOLLARS |
1 | 2 | 3 | 4 | 500000 |
1 | 4 | 2 | 1 | 200000 |
1 | 7 | 4 | 1 | 150000 |
BRIDGE_PI_GROUP
| PI_GROUP_KEY | PI_KEY |
2 | 16 |
2 | 34 |
4 | 16 |
4 | 27 |
4 | 28 |
7 | 16 |
PRINCIPAL_INVESTIGATOR_DIM
| PI_KEY | PI_PID | PI_LAST_NAME | PI_FIRST_NAME |
16 | 1000000001 | Smith | John |
27 | 1000009999 | Jones | Steven |
28 | 1001009879 | Doe | Lisa |
34 | 1009824467 | Brown | Robert |
For our ETL process, we believe we would need another group table consisting of the PI_GROUP_KEY from the BRIDGE_PI_GROUP table, and a second column concatenating the values of the Principal Investigator natural key (PI_PID, in this case) in order to form distinct groups of PI's and assign a PI group key.
We believe that we would take the same approach to address this with our organization dimension (its basically the same issue) but were hoping to solicit feedback as to whether we are taking the correct approach in designing this? I'm inserting a screenshot of our proposed diagram below.
This is the first star schema I'll be working on, so any advice or feedback would be very much appreciated (especially related to whether the bridge table would work for our situation, but if you have other advice/feedback, I'd definitely appreciate that as well!). Thank you!
CSH- Posts : 1
Join date : 2015-07-13
» Question on symmetry in Star schema
» Star Schema Design Question
» Simple Star schema question
» Star schema or using reference tables?
» Mulitple Fact Tables in a Star Schema
» Star Schema Design Question
» Simple Star schema question
» Star schema or using reference tables?
» Mulitple Fact Tables in a Star Schema
Page 1 of 1
Permissions in this forum:
You cannot reply to topics in this forum