
Modelling free text comments
3 posters
Page 1 of 1

Modelling free text comments
![]() memphis Sun Oct 24, 2010 6:42 pm
memphis Sun Oct 24, 2010 6:42 pm
Hi all,
I have a free text comment field that the business requires but I'm not sure what the best way to model this in my star schema would be, so just looking for a bit of advice. I have included my current star schema here:
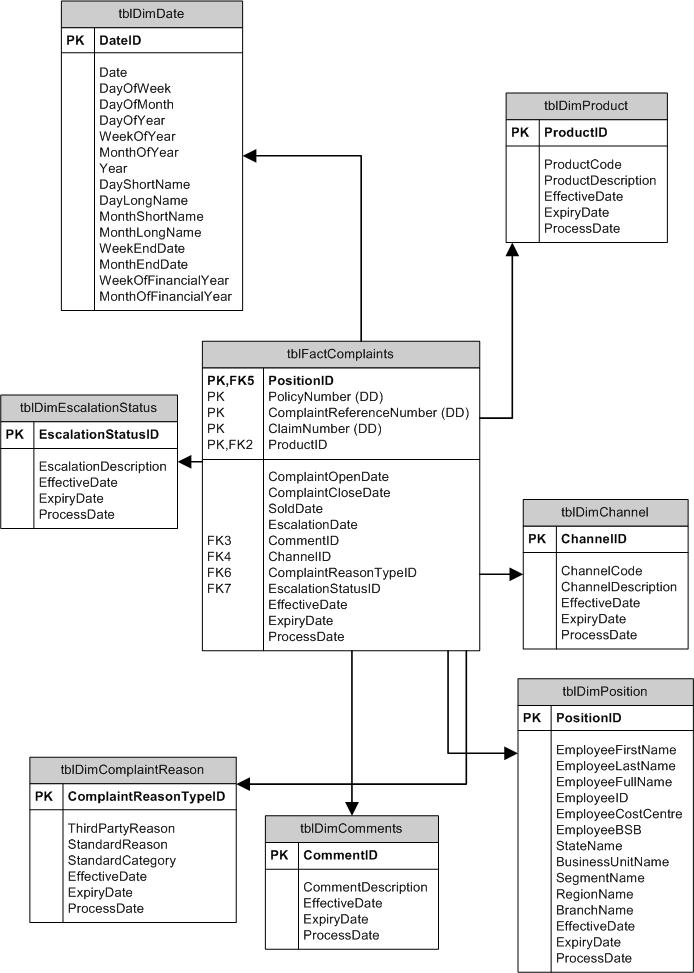
I am modelling complaints so in my current design, I have 1 complaint per row. The problem is each complaint has with it a 'comments' field. Now this field is truly free text and could be as small as 10 words, or it could be as huge as a whole 'letter of complaint'. The business is not going to standardize these comments in any way so I am going to have to live with the free text.
Based on my reading of Kimball, the recommended approach is to have the comments in a dimension on its own as I have done here. Is what I've done here correct? The thing is, I will be essentially having as many rows in my comments dimension as there are in my fact table. Would this be a problem? I don't see how I can get around this since all comments are free text.
Also if you take a look at the tblDimEscalationStatus dimension, would it be advisable to merge this dimension into the tblDimComments dimension so that it becomes a junk dimension? The Escalation status is actually standardized so my gut feeling is to leave it as a separate dimension.
Finally, just on the subject of slowing changing dimensions, I have decided to track changes with expiry and effective dates. So if for example a complaint (made in August) had its reason changed in (say October), I would expire the original record and insert a new record linked to the updated reason. In this way, when users query a report for August, they would see the original complaint as it was entered in August. If they however query a report spanning from August to October, they would see the updated complaint as it was changed in October. What is the correct technical term for this. Is it called 'As at' or 'As of' reporting?
I hope this all makes sense and if I could get some advice, that would be great!
Thanks very much.
I have a free text comment field that the business requires but I'm not sure what the best way to model this in my star schema would be, so just looking for a bit of advice. I have included my current star schema here:
I am modelling complaints so in my current design, I have 1 complaint per row. The problem is each complaint has with it a 'comments' field. Now this field is truly free text and could be as small as 10 words, or it could be as huge as a whole 'letter of complaint'. The business is not going to standardize these comments in any way so I am going to have to live with the free text.
Based on my reading of Kimball, the recommended approach is to have the comments in a dimension on its own as I have done here. Is what I've done here correct? The thing is, I will be essentially having as many rows in my comments dimension as there are in my fact table. Would this be a problem? I don't see how I can get around this since all comments are free text.
Also if you take a look at the tblDimEscalationStatus dimension, would it be advisable to merge this dimension into the tblDimComments dimension so that it becomes a junk dimension? The Escalation status is actually standardized so my gut feeling is to leave it as a separate dimension.
Finally, just on the subject of slowing changing dimensions, I have decided to track changes with expiry and effective dates. So if for example a complaint (made in August) had its reason changed in (say October), I would expire the original record and insert a new record linked to the updated reason. In this way, when users query a report for August, they would see the original complaint as it was entered in August. If they however query a report spanning from August to October, they would see the updated complaint as it was changed in October. What is the correct technical term for this. Is it called 'As at' or 'As of' reporting?
I hope this all makes sense and if I could get some advice, that would be great!
Thanks very much.
memphis- Posts : 19
Join date : 2010-10-21
Re: Modelling free text comments
![]() hang Sun Oct 24, 2010 7:43 pm
hang Sun Oct 24, 2010 7:43 pm
The free text comment in your case may best be left in the fact as a degenerated dimension. I cant see any point in creating a separate dimension table with only one comment field and additional surrogate key in it, while it has almost the same rows as many as in the fact, especially when the comment could be used as some kind of measures (eg. count on terms). However in some cases, comment fields are only sparsely populated or can be somehow standardised. So having comment dimension in many cases is still good practice as it can cater for non-existence and provide lookup items more efficiently.
For your last question, it depends on your business definition. In general terms, I refer to these two different views of the dimension as historical and current view (or profile) respectively.
For your last question, it depends on your business definition. In general terms, I refer to these two different views of the dimension as historical and current view (or profile) respectively.
hang- Posts : 528
Join date : 2010-05-07
Location : Brisbane, Australia
Re: Modelling free text comments
![]() memphis Sun Oct 24, 2010 8:17 pm
memphis Sun Oct 24, 2010 8:17 pm
Thanks hang for your response.
I initially had the 'comments' as part of the fact table, however I read that this may have a bad impact on performance since comments can become quite large (in my case I could get an entire complaint letter pasted in the there) and by including it in the fact then it could slow down queries.
I guess it depends on the query, for my case, I will only be doing a count on the number of complaints per month, so by having the comments in the fact table, it wouldn't slow down a 'count' query.
On the other hand, looking at my sample data, I have 3 or 4 data sources and the comment field is only coming through from 1 data source. The other data sources don't have comments and would be populated with 'N/A'. So I think I will follow your advice on still having a separate dimension for comments because it is sparsely populated and can cater for non-existence.
What are your thoughts on this?
I initially had the 'comments' as part of the fact table, however I read that this may have a bad impact on performance since comments can become quite large (in my case I could get an entire complaint letter pasted in the there) and by including it in the fact then it could slow down queries.
I guess it depends on the query, for my case, I will only be doing a count on the number of complaints per month, so by having the comments in the fact table, it wouldn't slow down a 'count' query.
On the other hand, looking at my sample data, I have 3 or 4 data sources and the comment field is only coming through from 1 data source. The other data sources don't have comments and would be populated with 'N/A'. So I think I will follow your advice on still having a separate dimension for comments because it is sparsely populated and can cater for non-existence.
What are your thoughts on this?
memphis- Posts : 19
Join date : 2010-10-21
Re: Modelling free text comments
![]() hang Sun Oct 24, 2010 8:51 pm
hang Sun Oct 24, 2010 8:51 pm
After your further explanation, it makes better sinse to have a separate comment dimension recommended by Kimball. The point is you dont want to repeat N/A for most of fact table rows. Having a N/A record in comment dimension and let FK in the fact table to work out whether the comment is substantial or inapplicable would be a better approach. The fact table would also become more normalised and compact which is good for dimensional modelling and performance.
hang- Posts : 528
Join date : 2010-05-07
Location : Brisbane, Australia
Re: Modelling free text comments
![]() ngalemmo Mon Oct 25, 2010 12:22 pm
ngalemmo Mon Oct 25, 2010 12:22 pm
The comment dimension is fine, however I question the use of effective/expiration and process dates in the dimension... they seem to duplicate dates on the fact.
Do comments expire? If they are tied to a fact, I would think they would not. The fact FK is sufficient to track the comment. If the comment changes, by your description, you will be creating a new fact row that references another comment value. There is no need to track comment history as that is covered in the fact relationships.
If process date is a system timestamp to track when the row was added, that's fine.
Another thing you should consider is to assume you will get a lot of the same comments... people are creatures of habit.
What I normally do is store a comment once. To do this, I generate a checksum of the text (I like to use the CRC32 function) and use that as a non-unique natural key to the dimension (with index). To get the surrogate key, I calculate the CRC32 value for the incomming comment and use the checksum and text to locate the dimension row. If I get a match, I use that key, otherwise I create a row. The reason for the checksum is to provide a small value (an integer) for indexing. You will get duplicates, so lookups must match text values as well, but it avoids having to index the text itself.
This will keep the size of the table to a minimum.
Do comments expire? If they are tied to a fact, I would think they would not. The fact FK is sufficient to track the comment. If the comment changes, by your description, you will be creating a new fact row that references another comment value. There is no need to track comment history as that is covered in the fact relationships.
If process date is a system timestamp to track when the row was added, that's fine.
Another thing you should consider is to assume you will get a lot of the same comments... people are creatures of habit.
What I normally do is store a comment once. To do this, I generate a checksum of the text (I like to use the CRC32 function) and use that as a non-unique natural key to the dimension (with index). To get the surrogate key, I calculate the CRC32 value for the incomming comment and use the checksum and text to locate the dimension row. If I get a match, I use that key, otherwise I create a row. The reason for the checksum is to provide a small value (an integer) for indexing. You will get duplicates, so lookups must match text values as well, but it avoids having to index the text itself.
This will keep the size of the table to a minimum.

ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -

Re: Modelling free text comments
![]() memphis Mon Oct 25, 2010 6:31 pm
memphis Mon Oct 25, 2010 6:31 pm
Thanks for you suggestions hang and ngalemmo.
Yes, my process date is used to track when the row was added.
Yeah I think you are correct. I guess because each comment is tied to the fact, then when a comment gets updated, I simply expire the original fact and insert a new fact row that will reference a new comment. I will get rid of the expire/effective dates in my comment dimension.
What about using the Hashbytes function in SQL Server? (I'm using Sql Server 2008). This way I can get a unique hash?
Yes, my process date is used to track when the row was added.
Do comments expire? If they are tied to a fact, I would think they would not. The fact FK is sufficient to track the comment. If the comment changes, by your description, you will be creating a new fact row that references another comment value. There is no need to track comment history as that is covered in the fact relationships"
Yeah I think you are correct. I guess because each comment is tied to the fact, then when a comment gets updated, I simply expire the original fact and insert a new fact row that will reference a new comment. I will get rid of the expire/effective dates in my comment dimension.
A very good suggestion. I will consider this approach but would just like to clarify, so I would have a column that stores the CRC checksum? So when I do a match, you're saying that because the CRC is not unique, i would need to match on the CRC column as well as the actual comment text to determine if I should insert a new comment or use the existing one?
To do this, I generate a checksum of the text (I like to use the CRC32 function) and use that as a non-unique natural key to the dimension (with index). To get the surrogate key, I calculate the CRC32 value for the incomming comment and use the checksum and text to locate the dimension row.
What about using the Hashbytes function in SQL Server? (I'm using Sql Server 2008). This way I can get a unique hash?
memphis- Posts : 19
Join date : 2010-10-21
Re: Modelling free text comments
![]() ngalemmo Tue Oct 26, 2010 12:41 pm
ngalemmo Tue Oct 26, 2010 12:41 pm
The idea is to keep the natural key index small. A 32 bit CRC is a small hash. It has over 4 billion possible values, but that is not enough to avoid collisions as the size of the comments table grows. But, the number of collisions are small, when the hash is used to locate the row, most of the time (98% or more) there will be only one row, but, occasionally there may be 2 or 3 rows. Having the database scan 2 or 3 rows every now and then would not hamper performance.
There are other hashes, such as MD5, which generates a 160 bit hash, but it doesn't, in my opinion, offer much of an advantage in this particular application. It will, in all probability, generate a unique hash key, but the larger index size offsets any performance improvement by eliminating the occasional scan.
I don't know what algorithm the Hashbytes function uses, but unless the hash is the size of an MD5 (2^160 possible values), I would not expect to use the value as a unique key. The problem with hashing collections is the probability of a collision increases rapidly as the population of the collection grows. A real-world example of this is: if you have 31 people in a room, the probability that any two people would have the same birthday is around 50%. In other words, if you have a hash with 365 possible values, and a table with 31 rows, there is a better than even chance that there will be a collision when you add the 32nd row.
So anyway, you have a column in the table to store the hash value and define a non-unique index on that column. Do not index the text column. Lookup queries would check both the hash and text values to locate an existing row.
There are other hashes, such as MD5, which generates a 160 bit hash, but it doesn't, in my opinion, offer much of an advantage in this particular application. It will, in all probability, generate a unique hash key, but the larger index size offsets any performance improvement by eliminating the occasional scan.
I don't know what algorithm the Hashbytes function uses, but unless the hash is the size of an MD5 (2^160 possible values), I would not expect to use the value as a unique key. The problem with hashing collections is the probability of a collision increases rapidly as the population of the collection grows. A real-world example of this is: if you have 31 people in a room, the probability that any two people would have the same birthday is around 50%. In other words, if you have a hash with 365 possible values, and a table with 31 rows, there is a better than even chance that there will be a collision when you add the 32nd row.
So anyway, you have a column in the table to store the hash value and define a non-unique index on that column. Do not index the text column. Lookup queries would check both the hash and text values to locate an existing row.
ngalemmo- Posts : 3000
Join date : 2009-05-15
Location : Los Angeles -
» Handling multiple free form text comments
» Storing text comments in a data warehouse
» Free form text in transaction table
» Free text fields in Transaction table
» Free Form Text Attribute in Fact Table
» Storing text comments in a data warehouse
» Free form text in transaction table
» Free text fields in Transaction table
» Free Form Text Attribute in Fact Table
Page 1 of 1
Permissions in this forum:
You cannot reply to topics in this forum